Introduction to speech features¶
Implemented models¶
The following features extraction models are implemented in
shennong, the detailed documentation is available here:Features
Implementation
Spectrogram
from Kaldi
Filterbank
from Kaldi
MFCC
from Kaldi
PLP (optional Rasta filtering)
Bottleneck
from BUTspeech
One Hot Vectors
shennong
Pitch
Energy
from Kaldi
The following post-processing pipelines are implemented in
shennong, the detailed documentation is available here:Post-processing
Implementation
Delta / Delta-delta
from Kaldi
Mean Variance Normalization (CMVN)
from Kaldi
Voice Activity Detection
from Kaldi
Vocal Tract Length Normalization (VTLN)
from Kaldi
Here is an illustration of the features (without post-processing) computed on the example wav file provided as
shennong/test/data/test.wav, this picture can be reproduced using the example scriptshennong/examples/plot_features.py: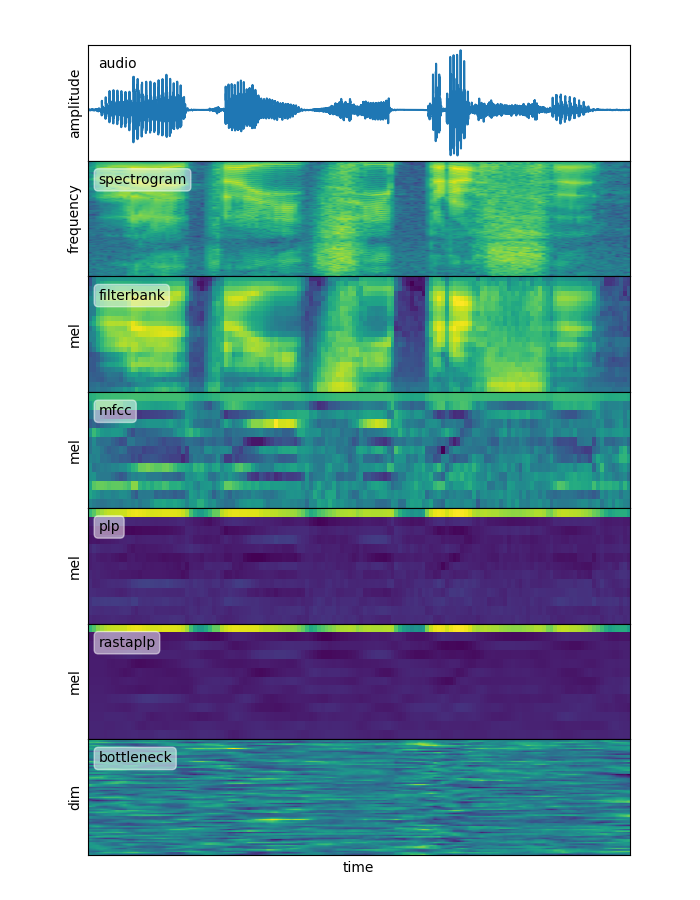
Features comparison¶
This section details a phone discrimination task based on the features
available in shennong. It reproduces the track 1 of the Zero
Speech Challenge 2015
using the same datasets and setup. The recipe to replicate this
experiment is available at shennong/examples/features_abx.
Setup:
Two languages are tested:
English (Buckeye corpus, 12 speakers for a duration of 10:34:44)
Xitsonga (NCHLT corpus, 24 speakers for a duration of 4:24:37)
The considered features extraction algorithms are:
Spectrogram
Mel Filterbanks
MFCC
PLP (with and with Rasta filtering)
Bottleneck
Each is tested with 3 distinct parameters sets, with and without VTLN:
raw: the raw features only,
+∆/F0: raw features with delta, delta-delta and Kaldi pitch estimates,
+CMVN: raw features with CMVN normalization by speaker, with delta, delta-delta and Kaldi pitch estimates.
The considered ABX tasks are the same as in the ZRC2015 track1, namely a phone discrimination task within and across speakers.
Note
The results are ABX error rates on phone discrimination (given in %, random score is 50%).
Results on English across speakers:
features
without VTLN
with VTLN
raw
+∆/F0
+CMVN
raw
+∆/F0
+CMVN
spectrogram
30.3
27.9
29.7
filterbank
24.9
22.1
26.5
23.2
20.7
25.4
mfcc
27.2
26.4
24.0
23.4
22.7
20.0
plp
28.0
26.6
23.8
24.7
23.5
19.7
rastaplp
28.5
26.8
25.3
24.6
23.6
21.3
bottleneck
12.5
12.5
12.5
Results on English within speakers:
features
without VTLN
with VTLN
raw
+∆/F0
+CMVN
raw
+∆/F0
+CMVN
spectrogram
16.7
15.2
20.2
filterbank
12.8
11.6
18.2
12.6
11.4
18.1
mfcc
13.0
12.5
12.4
12.8
12.3
12.0
plp
12.5
12.4
11.9
12.5
12.4
11.9
rastaplp
14.3
14.2
12.5
14.2
14.1
12.5
bottleneck
8.5
8.5
8.6
Results on Xitsonga across speakers:
features
without VTLN
with VTLN
raw
+∆/F0
+CMVN
raw
+∆/F0
+CMVN
spectrogram
34.6
32.0
26.5
filterbank
28.1
25.1
21.5
26.9
24.0
20.7
mfcc
33.6
32.8
26.0
31.4
30.6
22.7
plp
33.5
31.2
26.2
31.7
29.5
22.2
rastaplp
27.9
25.2
23.9
25.0
22.8
21.7
bottleneck
9.5
9.6
9.6
Results on Xitsonga within speakers:
features
without VTLN
with VTLN
raw
+∆/F0
+CMVN
raw
+∆/F0
+CMVN
spectrogram
19.2
16.8
19.2
filterbank
13.8
11.7
15.2
13.6
11.4
15.2
mfcc
17.1
16.2
14.6
17.5
16.5
14.6
plp
16.2
14.6
14.0
16.2
14.7
14.2
rastaplp
13.7
12.5
12.3
13.5
12.2
12.0
bottleneck
6.9
7.0
7.3
Comparison with the ZRC2015 baseline (on MFCC only), see [Versteegh2015]:
English
Xitsonga
across
within
across
within
ZRC2015
28.1
15.6
33.8
19.1
shennong raw
27.2
13.0
33.6
17.1
shennong +CMVN
24.0
12.4
26.0
14.6
ZRC2015 VTLN
24.0
14.6
shennong VTLN raw
23.4
12.8
31.4
17.5
shennong VTLN +CMVN
20.0
12.0
22.7
14.2
- Versteegh2015
The zero resource speech challenge 2015, Maarten Versteegh, Roland Thiollière, Thomas Schatz, Xuan-Nga Cao, Xavier Anguera, Aren Jansen, and Emmanuel Dupoux. In INTERSPEECH-2015. 2015.
- Can2018
PyKaldi: A Python Wrapper for Kaldi, Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and Shrikanth S. Narayanan, in IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), 2018.