Random Baseline¶
Note
wordseg.algo.baseline in python, wordseg-baseline in bash.
Baseline algorithm for word segmentation
This algorithm randomly adds word boundaries after the input tokens with a given probability.
-
wordseg.algos.baseline.segment(text, probability=0.5, log=<RootLogger root (WARNING)>)[source]¶ Random word segmentation given a boundary probability
Given a probability
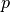 , the probability
, the probability 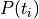 to
add a word boundary after each token
to
add a word boundary after each token 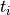 is:
is: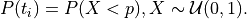
- Parameters
text (sequence) – The input utterances to segment, tokens are assumed to be space separated.
probability (float, optional) – The probability to append a word boundary after each token.
log (logging.Logger) – Where to send log messages
- Yields
segmented_text (generator) – The randomly segmented utterances.
- Raises
ValueError – if the probability is not a float in [0, 1].
-
wordseg.algos.baseline.segment_oracle(text, oracle_text, oracle_separator=<wordseg.separator.Separator object>, oracle_level='phone', log=<RootLogger root (WARNING)>)[source]¶ Random oracle word segmentation
The probability of word boundary
is estimated from an
oracle text as the ration nwords / (nphones or nsyllables), according tooracle_level. The segmentation is then delegated to the segment(text,) method is called.- Parameters
text (sequence of str) – The input utterances to segment, tokens are assumed to be space separated.
oracle_text (sequence of str) – The text on which to estimate the probaility of word boundary. Must be tokenized at word and at least phone or syllable levels (according to
oracle_level).oracle_separator (Separator, optional) – Token separation in the oracle text.
oracle_level (str, optional) – The level to consider when estimating
, must be
‘phone’ or ‘syllable’, default to ‘phone’.log (logging.Logger) – Where to send log messages
- Yields
segmented_text (generator) – The randomly segmented utterances.