Descriptive Statistics¶
Extract statistics relevant for word segmentation corpora
To analyze a segmented text or a text in orthographic form (i.e. with word separators only), you must define empty phone and syllable separators (see the token separation arguments below).
-
class
wordseg.statistics.CorpusStatistics(corpus, separator, log=<RootLogger root (WARNING)>)[source]¶ Bases:
objectEstimates descriptive statistics from a text corpus
- Parameters
corpus (sequence of str) – The text to describe is a suite of tokenized utterances.
separator (Separator) – The token separators used in the text.
log (logging.Logger) – Where to send log messages, disabled by default.
-
tokens¶ For all levels defined in separator, tokens[level] is the corpus utterances tokenized at that level. Each utterance is a list of tokens without any separator.
- Type
dict
-
unigram¶ For all levels defined in separator, unigram[level] is the tokens frequency as a dict (token: frequency).
- Type
dict
-
describe_all()[source]¶ Full description of the corpus at utterance and token levels
This method is a simple wrapper on the other statistical methods. It call all the methods available for the defined separator (some of them requires ‘phone’ tokens) and wraps the results in an ordered dictionary.
-
describe_corpus()[source]¶ Basic description of the corpus at word level
- Returns
stats – A dictionnary made of the following entries (all counts being on the entire corpus):
’nutts’: number of utterances
’nutts_single_word’: number of utterances made of a single world
’mattr’: mean ratio of unique words per chunk of 10 words
- Return type
ordered dict
Notes
This method is a Python implementation of this script from CDSWordSeg.
-
describe_tokens(level)[source]¶ Basic description of the corpus at tokens level
- Parameters
level (str) – The tokens level to describe. Must be ‘phone’, ‘syllable’ or ‘word’.
- Returns
stats – A dictionnary made of the following entries (all counts being on the entire corpus):
’tokens’: number of tokens
’types’: number of types
’hapaxes’: number of types occuring only once in the corpus
- Return type
ordered dict
-
most_common_tokens(level, n=None)[source]¶ Return the most common tokens and their count
- Parameters
level (str) – Must be ‘phone’, ‘syllable’ or word’.
n (int, optional) – When specified returns only the n most commons tokens, when omitted or None returns all the tokens.
- Returns
counts – The list of (token, count) values sorted in decreasing count order.
- Return type
list
-
normalized_segmentation_entropy()[source]¶ Return the Normalized Segmentation Entropy computed on text
Token separators must be defined for phones and words.
- Returns
entropy – The estimated NSE in bits.
- Return type
float
- Raises
KeyError if the corpus is not tokenized at 'phone' and 'word' levels. –
Notes
As explained in 1 we are interested in the ambiguity generated by the different possible parses that result from a segmentation. In order to quantify this idea in general, we define a Normalized Segmentation Entropy. To do this, we need to assign a probability to every possible segmentation. To this end, we use a unigram model where the probability of a lexical item is its normalized frequency in the corpus and the probability of a parse is the product of the probabilities of its terms. In order to obtain a measure that does not depend on the utterance length, we normalize by the number of possible boundaries in the utterance. So for an utterance of length N, the Normalized Segmentation Entropy (NSE) is computed using Shannon formula (Shannon, 1948) as follows:
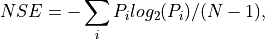
where
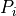 is the probability of the word
is the probability of the word 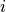 and
and
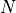 the number of phonemes in the text.
the number of phonemes in the text.- 1
A. Fourtassi, B. Börschinger, M. Johnson and E. Dupoux, “Whyisenglishsoeasytosegment”. In Proceedings of the Fourth Annual Workshop on Cognitive Modeling and Computational Linguistics (pp. 1-10), 2013.